為了讓自己在機器學習實作上更多實務經驗,經過搜尋之後,在網路上找到了不錯的資源
下面分享兩個非常受歡迎的機器學習競賽網站
分別是 Kaggle 與 天池大数据竞赛
它們提供有趣的題目與資料,讓參賽者比賽誰的訓練模形比較出眾
提交答案之後,它們會提供排名讓你知道你的模形是好還是不好
兩者比較 : 知乎-天池大数据竞赛和Kaggle、DataCastle的比较,哪个比较好?
2017年3月25日 星期六
簡單但有效的學習方法
Newbie
新生大学郑伊廷:学习就像打游戏,你通关没?
Xdite:永葆热情的上瘾式学习法
學習的「黃金通道」
領悟「學習的黃金通道」
Expert
怎样练习一万小时
做筆記的技巧
ORID 原則、如何使用ORID总结学习,加快进步?
新生大学郑伊廷:学习就像打游戏,你通关没?
Xdite:永葆热情的上瘾式学习法
學習的「黃金通道」
領悟「學習的黃金通道」
Expert
怎样练习一万小时
做筆記的技巧
ORID 原則、如何使用ORID总结学习,加快进步?
[Tensorflow] Tensorflow 中的 ALexNet VGGNet GoogleLeNet(Inception-v1) 實作
先說結論:要了解實做細節,Tensorflow官方Github有很多寶貝可以挖
使用常見的類神經網路
Tensorflow 的其實很佛心的把各種不同常用的的神經網路實做出來包含時常作為Benchmark的 AlexNet、VGGNet、GoogleLeNet(Inception-v1)、ResNet等
VGGNet 使用教學範例
在這篇教學文 TF-Slim Walkthrough 中
教我們如何使用 Tensorflow 中的VGGNet 來作為影像分類器
另一個VGGNet範例: Working example: Tracking Multiple Metrics
如果需要哪個類神經網絡架構,可以把它預先訓練好的參數 (ckpt) 檔拿來使用
其他預先訓練的參數檔案 在此
ps. 連2016最新的類神經網路架構 Inception-ResNet-v2 也有
如果有需要使用test dataset Downloading and converting to TFRecord format 教我們怎下載與轉成 tfrecords 檔
TF slim Module
如官方的BlogTF-Slim: A high level library to define complex models in TensorFlow
文中所說的,TF slim 是一個用來定義模型的輕量化函式庫(Libraries)
The Inception-V3 model was built on an experimental TensorFlow library called TF-Slim, a lightweight package for defining, training and evaluating models in TensorFlow而本文的重點在此
Code to define and train many widely used image classification models (e.g., Inception[1][2][3], VGG[4], AlexNet[5], ResNet[6]).此外
Since that release, TF-Slim has grown substantially, with many types of layers, loss functions, and evaluation metrics added, along with handy routines for training and evaluating models. These routines take care of all the details you need to worry about when working at scale, such as reading data in parallel, deploying models on multiple machines, and more.從文中就可以發現,Google 已經將實做的部份幫我們完成了!
所以往後如果要測試不同的神經網絡架構,只需要Tensorflow 的 TF slim 裡面叫出來使用即可
源始碼
先從 Tensorflow 的其中一個專門存放 models 的 repository 來看,進入到 inception 的資料夾打開 imagenet_train.py 的源始碼中可以看到,它使用的是 inception 這種類神經網路架構
而在 inception 模組中的 inception_train.py 中可以看到它有使用到 TF slim 模組
from inception.slim import slim練習實作
當然,閱讀了這多文獻、文章,還是需要大家自己親手實做一個神經網落是最有感覺的
Tensorflow 官網的這篇教學文章
提供我們一個手把手的教學,幫助我們了解怎從零打造一個 CNN 類神經網路
[Tensorflow] 將圖片轉成 TFRecords 檔案
如何將影像訓練資料轉成 Tensorflow可以讀的 TFrecords 檔?
嘗試可行方案
透過 build_image_data.py 轉成 TFrecords 檔
For inception-v3 model
1. 方案1在Tensorflow官方的Github上
How to Construct a New Dataset for Retraining
Briefly, this script takes a structured directory of images and converts it to a sharded TFRecord that can be read by the Inception model.
教我們如何產生 Inception model 可以讀的 TFrecords 格式
如果有安裝Bazel這個Google內部使用的 make file 工具的話
按照裡面的指令,就能夠將影像資料轉成 tfrecords 檔
步驟1: 先準備好 訓練資料的資料夾 & 驗證資料的資料夾
以及負責標籤的 labels.txt 檔( txt 檔裡面只有資料夾名稱,一個資料夾一行,其餘用換行鍵隔開)
步驟2:
bazel-bin/inception/build_image_data \ # 照著輸入即可
--train_directory="${TRAIN_DIR}" \ # 輸入訓練資料夾位置
--validation_directory="${VALIDATION_DIR}" \ # 輸入驗證資料夾位置
--output_directory="${OUTPUT_DIRECTORY}" \ # 輸出 tfrecords 檔的路徑
--labels_file="${LABELS_FILE}" \ #裡面只有資料夾名稱,即有哪些資料夾需要處理
--train_shards=128 \ # 照著輸入即可
--validation_shards=24 \ # 照著輸入即可
--num_threads=8 # 照著輸入即可
以及負責標籤的 labels.txt 檔( txt 檔裡面只有資料夾名稱,一個資料夾一行,其餘用換行鍵隔開)
步驟2:
bazel-bin/inception/build_image_data \ # 照著輸入即可
--train_directory="${TRAIN_DIR}" \ # 輸入訓練資料夾位置
--validation_directory="${VALIDATION_DIR}" \ # 輸入驗證資料夾位置
--output_directory="${OUTPUT_DIRECTORY}" \ # 輸出 tfrecords 檔的路徑
--labels_file="${LABELS_FILE}" \ #裡面只有資料夾名稱,即有哪些資料夾需要處理
--train_shards=128 \ # 照著輸入即可
--validation_shards=24 \ # 照著輸入即可
--num_threads=8 # 照著輸入即可
2. 方案2
註:與 How to Retrain a Trained Model on the Flowers Data(較小資料量的訓練 (218 MB)) 類似的內容
For pre-trained model
之前利用NVIDIA官網上的教學
則是可以產生 已經訓練過的模型 (內有ckpt檔案的路徑,執行後會自動網路上下載)可以讀的 TFrecords 格式
因為不想要改動原本裡面內建的腳本程式,所以另外複製了一份
並且更改檔案名稱
需要小心的是,如果今天創造了一個新的程式
需要在 inception/data 裡面有一個檔案叫作 BUILD 的txt檔案裡面加上它需要的資訊
最簡單的作法是找到原本檔案的資訊,名稱以及對應的檔案改成新的檔案名就可以了
---(暫不採用)寫一個腳本程式(script ) ---
原因:因為需要考慮bazel這個建置程式可能造成的影響(ex. 只能在特定資料夾下處理)
所以直接拿Tensorflow models資料夾中的腳本直接來修改比較省時間
-------------------------------------------------------------------------------------------
背景知識補充 : 認識與學習BASH、學習 Shell Scripts
參考以下的文章
How do I create a script file for terminal commands?
以 vim 打開一個程式任意的撰寫畫面
請務必確保在第一行寫下以下的程式
#!/bin/bash
接著,再將該程式標示為可執行
chmod +x 檔案名稱
What does set -e mean in a bash script?
What does -z mean in Bash?
Bazel
使用bazel build之前記得開一個worksapce,這邊的通關密碼是輸入
touch WORKSPACE
相關 bazel 建置的問題 : The 'build' command is only supported from within a workspace
後來去查 Bazel 的官方使用教學的 Using a Workspace 這段也有提到這件事情
待嘗試...
教學文 Tfrecords Guide :執行 python code 產生 tfrecords 檔
Python
新創一個 python 檔案在命令列視窗裡面以vim開啟一個結尾是.py的檔案
$ vim filename.py
進入vim編輯的畫面之後
記得在第一行加上下列的程式碼
#!/usr/bin/python
按下 [Esc] 鍵之後,輸入冒號符號: 和英文字母 wq,代表寫入(Write)並離開(Quit)的意思
2017年3月23日 星期四
[Tensorflow] 以 Tensorlfow 內建的 Timeline 函數來作為 profiling 工具
最近對手邊沒有一個比較好的 Tensorflow profiling工具感到發愁的時候
在網路上搜尋資訊的時候剛好看到下面這篇 stackoverflow 的文章
Can I measure the execution time of individual operations with TensorFlow?
裡面就提到了 Tensorflow 裡面內建的 Timeline 這個函數
另外,Github 上面的也有類似的疑問
Profiling tools for open source TensorFlow #1824
其中,prb12 也提到 Timeline 這個函數,並提供了簡單的文字教學 :
打開 Chrome,並在網址尋列輸入:Chrome://tracing 就有簡單的 gui 能夠使用
按下Load,選取剛創造的json檔案,就能夠將前一個時刻創造的 Timeline 圖表給呈現出來
在網路上搜尋資訊的時候剛好看到下面這篇 stackoverflow 的文章
Can I measure the execution time of individual operations with TensorFlow?
裡面就提到了 Tensorflow 裡面內建的 Timeline 這個函數
另外,Github 上面的也有類似的疑問
Profiling tools for open source TensorFlow #1824
其中,prb12 也提到 Timeline 這個函數,並提供了簡單的文字教學 :
I'm unlikely to have much time to write a tutorial in the near future, but the current status of the open source tools are as follows:
There is now a basic CUPTI GPU tracer integrated in the runtime. You can run a step with tracing enabled and it records both the ops which are executed and the GPU kernels which are launched. Here is an example:
run_metadata = tf.RunMetadata()
_, l, lr, predictions = sess.run(
[optimizer, loss, learning_rate, train_prediction],
feed_dict=feed_dict,
options=tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE),
run_metadata=run_metadata)
After the step completes, the run_metadata should contain a StepStats protobuf with lots of timing information, grouped by tensorflow device. The CUPTI GPU tracing appears as some additional devices with names like /gpu:0/stream:56 and /gpu:0/memcpy
Note: to get GPU tracing you will need to ensure that libcupti.so is on you LD_LIBRARY_PATH. It is usually found in /usr/local/cuda/extras/lib64.
The simplest way to use this information is to load the stats into a 'Timeline' as follows:
from tensorflow.python.client import timeline
trace = timeline.Timeline(step_stats=run_metadata.step_stats)
The Timeline class can then be used to emit a JSON trace file in the Chrome Tracing Format, as follows:
trace_file = open('timeline.ctf.json', 'w')
trace_file.write(trace.generate_chrome_trace_format())
To view this trace, navigate to the URL 'chrome://tracing' in a Chrome web browser, click the 'Load' button and locate the timeline file.
It would be fairly simple to write a small python web server which served up these traces from a running TensorFlow program like this
打開 Chrome,並在網址尋列輸入:Chrome://tracing 就有簡單的 gui 能夠使用
按下Load,選取剛創造的json檔案,就能夠將前一個時刻創造的 Timeline 圖表給呈現出來
2017年3月20日 星期一
[AI] 機器學習的記憶體使用
模型本身的大小(model size)計算
在下面的 pdf 中,Total memory requirements (train time) 那段有提到
Memory usage and computational considerations
同時在這篇文章也有提到
在這個問題 Why do convolutional neural networks use so much memory? [3] 中,也提到了
NN 的模型大小
也可以參考史丹佛大學的 CS231n Winter 2016 Lecture 11 ConvNets in practice 上課影片
訓練過程中的記憶體使用
讀取數據,會先從硬碟(Hard Disk)中讀出影像資訊存放到隨機存取記憶體(RAM)
再將暫存的影像資料從 RAM 搬到 GPU 內部的記憶體中
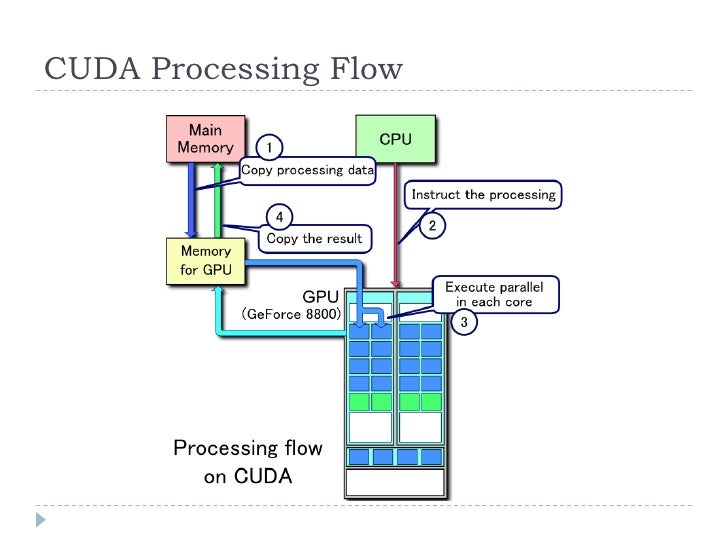
這些資料可能就高達數個GB之多,下面的文字有針對這件事情的描述:
至於運算下一個epoch的時候,則再從RAM裡面搬資料到GPU的記憶體中
另外,如果batch size調大的話,影像資料就會佔用較大的記憶體空間
Ex. 原本batch size = 32, 改成 64 的話,在執行迴圈中的每一輪訓練過程,佔用的記憶體的增長速度就會變成兩倍
也可以參考此篇 A Full Hardware Guide to Deep Learning 的文章
從 Asynchronous mini-batch allocation 到 Hard drive/SSD 的部份即可
[1] Memory usage and computational considerations
[2] Why is so much memory needed for deep neural networks?
在下面的 pdf 中,Total memory requirements (train time) 那段有提到
Memory usage and computational considerations
同時在這篇文章也有提到
Memory in neural networks is required to store input data, weight parameters and activations as an input propagates through the network.
In training, activations from a forward pass must be retained until they can be used to calculate the error gradients in the backwards pass.
As an example, the 50-layer ResNet network has ~26 million weight parameters and computes ~16 million activations in the forward pass. If you use a 32-bit floating-point value to store each weight and activation this would give a total storage requirement of 168 MB.
By using a lower precision value to store these weights and activations we could halve or even quarter this storage requirement. [2]
在這個問題 Why do convolutional neural networks use so much memory? [3] 中,也提到了
NN 的模型大小
也可以參考史丹佛大學的 CS231n Winter 2016 Lecture 11 ConvNets in practice 上課影片
訓練過程中的記憶體使用
讀取數據,會先從硬碟(Hard Disk)中讀出影像資訊存放到隨機存取記憶體(RAM)
再將暫存的影像資料從 RAM 搬到 GPU 內部的記憶體中
這些資料可能就高達數個GB之多,下面的文字有針對這件事情的描述:
A greater memory challenge arises from GPUs' reliance on data being laid out as dense vectors so they can fill very wide single instruction multiple data (SIMD) compute engines, which they use to achieve high compute density.
CPUs use similar wide vector units to deliver high-performance arithmetic. In GPUs the vector paths are typically 1024 bits wide, so GPUs using 32-bit floating-point data typically parallelise the training data up into a mini-batch of 32 samples, to create 1024-bit-wide data vectors.
This mini-batch approach to synthesizing vector parallelism multiplies the number of activations by a factor of 32, growing the local storage requirement to over 2 GB. [2]
至於運算下一個epoch的時候,則再從RAM裡面搬資料到GPU的記憶體中
另外,如果batch size調大的話,影像資料就會佔用較大的記憶體空間
Ex. 原本batch size = 32, 改成 64 的話,在執行迴圈中的每一輪訓練過程,佔用的記憶體的增長速度就會變成兩倍
也可以參考此篇 A Full Hardware Guide to Deep Learning 的文章
從 Asynchronous mini-batch allocation 到 Hard drive/SSD 的部份即可
[1] Memory usage and computational considerations
[2] Why is so much memory needed for deep neural networks?
2017年3月19日 星期日
[AI] 循環式神經網路 (RNN, Recurrent Neural Networks) 介紹
[本人沒有文中的圖片版權,僅作為個人筆記使用而非商用]
Recurrent 劍橋辭典字面上的意思是 happening again many times
也就是重複發生非常多次的意思,至於為什麼,等等看結構圖就能夠約略明白
RNN (Recurrent Neural Networks) vs Feedforward NN (Neural Networks)
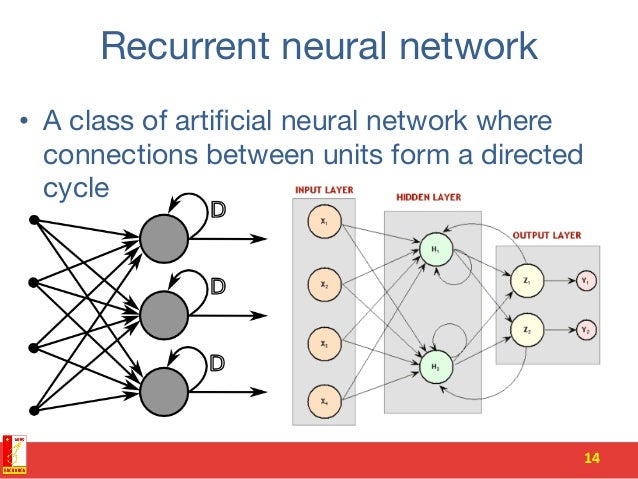
循環式神經網路與前饋式類神經網路不相同的地方在於
前饋式類神經網路,不同層之間有互相連接,同一層之間則未必,如下圖一所示


RNN 的設計哲學
這樣的設計是因為前饋式神經網路設計沒辦法因應需要前後關係的問題。
例如,自然語言處理(Natural Language Processing, NLP) 中,如果要預測下一個字詞,我們就需要前段的文字資訊才能判斷。[1]
如果是前饋式的類神經網路,在辨識照片上能夠取得不錯的結果,是因為辨識的照片之間,沒有前後關係。像是這張影像如果是貓,下張需要辨識的影像可能是大象,貓與大象之間是沒有邏輯上的直接相關性。
但是如果需要因應包含時間上順序(order)的問題,前饋式類神經網路就顯得力不從心。
但是RNN則不同,它的設計允許前一層的輸出能夠影響下一個時刻的輸出。意即是隱藏層(Hidden Layer)的神經元能夠接收到前一個時刻其他同層神經元,甚至自己本身的輸出的回饋(feedback)。因此,能根據前一輪記憶的結果來提昇推測下一個單字的準確度。[2]
RNN的展開
如果我們將下圖五左側的RNN結構給展開來,就會得到一個序列式的形式,如右側所示。
我們可以看到,隨著不同的時間點(t0, t1, t2, ...),就會能夠得到不同的輸出結果(h0, h1, h2, ...),最終,將結果合併起來,我們就可以得到最後的預測結果。
Recurrent 劍橋辭典字面上的意思是 happening again many times
也就是重複發生非常多次的意思,至於為什麼,等等看結構圖就能夠約略明白
RNN (Recurrent Neural Networks) vs Feedforward NN (Neural Networks)
循環式神經網路與前饋式類神經網路不相同的地方在於
前饋式類神經網路,不同層之間有互相連接,同一層之間則未必,如下圖一所示
圖一、傳統類神經網路
但是循環式神經網路,同一層的神經元之間則是彼此之間互相連接,甚至輸出之後也會聯回自己本身,如下圖二、三、四。

圖二、RNN -1
圖三、RNN -2
圖四、RNN -3
RNN 的設計哲學
這樣的設計是因為前饋式神經網路設計沒辦法因應需要前後關係的問題。
例如,自然語言處理(Natural Language Processing, NLP) 中,如果要預測下一個字詞,我們就需要前段的文字資訊才能判斷。[1]
如果是前饋式的類神經網路,在辨識照片上能夠取得不錯的結果,是因為辨識的照片之間,沒有前後關係。像是這張影像如果是貓,下張需要辨識的影像可能是大象,貓與大象之間是沒有邏輯上的直接相關性。
但是如果需要因應包含時間上順序(order)的問題,前饋式類神經網路就顯得力不從心。
但是RNN則不同,它的設計允許前一層的輸出能夠影響下一個時刻的輸出。意即是隱藏層(Hidden Layer)的神經元能夠接收到前一個時刻其他同層神經元,甚至自己本身的輸出的回饋(feedback)。因此,能根據前一輪記憶的結果來提昇推測下一個單字的準確度。[2]
RNN的展開
如果我們將下圖五左側的RNN結構給展開來,就會得到一個序列式的形式,如右側所示。
我們可以看到,隨著不同的時間點(t0, t1, t2, ...),就會能夠得到不同的輸出結果(h0, h1, h2, ...),最終,將結果合併起來,我們就可以得到最後的預測結果。
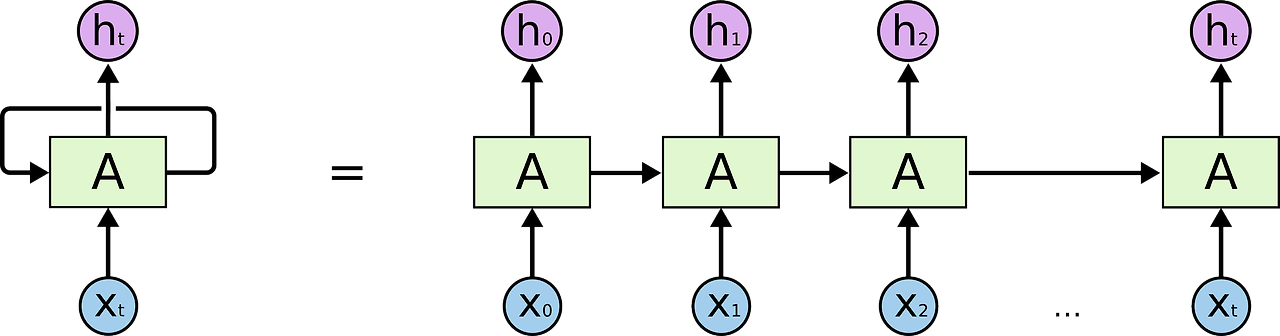
2017年3月17日 星期五
[ML] Coursera- Stanford University - Machine Learning - Week1 Linear Regression(線性迴歸)
授課教師是史丹佛大學大名鼎鼎的教授Andrew Ng
同時也是Coursera的創辦人與百度目前負責人工智慧項目的大頭之一
第一週教授的是第一個機器學習的模型 - Linear Regression(線性迴歸)
線性回歸的概念其實在高中的時候其實在統計的章節有教過
如果以下圖的二維平面為例,上面分佈了數個散佈的資料點,如何能夠找到代表這些資料的表達模型?

線性回歸就是想要回答這個問題
線性回歸想要找到最能夠表達這些資料點的直線
誤差(error)
透過嘗試不同的直線,我們計算理論直線上的數值與實際資料點,兩者差距值就是所謂的誤差 (真實世界:理想與現實的差距)

誤差的平方(square error)
上述的誤差算出來的數值,可能有正有負,但是誤差的正負號不管如何,都是誤差(不管黑貓白貓,能夠抓老鼠的都是好貓)
因此去掉正負,最能夠衡量真正的誤差。我們可以透過平方這件事情來做到,同時也可以拉開不同數值之間的差距
例如,正負1的平方是1,正負2的平方是4,正負三的平方是9,4和1之間的差距是3,9和4之間的差距是5,差距之間能夠拉大,能夠顯現出該項誤差代表的份量
誤差的平方和(Sum of square error)
如果要衡量兩條線(模型)哪一條最能夠符合我們處理的數據,最點單的想法就是把上述所有資料點的誤差平方加總起來,取誤差總值最小的線,就是最符合我們需求的結果

這個誤差的平方和,我們可以視作一個名詞叫作成本函數 (cost function)
這個概念的字面意思相當直觀,就是選取讓成本最低的直線,就是我們想要的答案
同時也是Coursera的創辦人與百度目前負責人工智慧項目的大頭之一
第一週教授的是第一個機器學習的模型 - Linear Regression(線性迴歸)
線性回歸的概念其實在高中的時候其實在統計的章節有教過
如果以下圖的二維平面為例,上面分佈了數個散佈的資料點,如何能夠找到代表這些資料的表達模型?

線性回歸就是想要回答這個問題
線性回歸想要找到最能夠表達這些資料點的直線
誤差(error)
透過嘗試不同的直線,我們計算理論直線上的數值與實際資料點,兩者差距值就是所謂的誤差 (真實世界:理想與現實的差距)

誤差的平方(square error)
上述的誤差算出來的數值,可能有正有負,但是誤差的正負號不管如何,都是誤差(不管黑貓白貓,能夠抓老鼠的都是好貓)
因此去掉正負,最能夠衡量真正的誤差。我們可以透過平方這件事情來做到,同時也可以拉開不同數值之間的差距
例如,正負1的平方是1,正負2的平方是4,正負三的平方是9,4和1之間的差距是3,9和4之間的差距是5,差距之間能夠拉大,能夠顯現出該項誤差代表的份量
誤差的平方和(Sum of square error)
如果要衡量兩條線(模型)哪一條最能夠符合我們處理的數據,最點單的想法就是把上述所有資料點的誤差平方加總起來,取誤差總值最小的線,就是最符合我們需求的結果

這個誤差的平方和,我們可以視作一個名詞叫作成本函數 (cost function)
這個概念的字面意思相當直觀,就是選取讓成本最低的直線,就是我們想要的答案
2017年3月16日 星期四
[GIT] 版本控制工具
為了要把檔案上傳到Github上面,因此開始使用Git這個常聽到的版本控制工具
最簡單的圖文教學首推 連猴子都能懂的Git入門指南
有任何情況,可以使用
git status
可以知道目前資料庫中的情況
git branch -a
如果有不同的branch,則可以將所有的分支(包含主branch)都羅列出來
最簡單的圖文教學首推 連猴子都能懂的Git入門指南
有任何情況,可以使用
git status
可以知道目前資料庫中的情況
git branch -a
如果有不同的branch,則可以將所有的分支(包含主branch)都羅列出來
2017年3月12日 星期日
[Tensorflow] 讀取影像檔的不同方式
Tensorflow 不只有一種讀取影像的方法
在這篇 TensorFlow高效读取数据 中,官方提供了3種方法
供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。 对于数据量较小而言,可能一般选择直接将数据加载进内存,然后再分batch输入网络进行训练(tip:使用这种方法时,结合yield 使用更为简洁,大家自己尝试一下吧,我就不赘述了)。但是,如果数据量较大,这样的方法就不适用了,因为太耗内存,所以这时最好使用tensorflow提供的队列queue,也就是第二种方法 从文件读取数据。对于一些特定的读取,比如csv文件格式,官网有相关的描述,在这儿我介绍一种比较通用,高效的读取方法(官网介绍的少),即使用tensorflow内定标准格式——TFRecords
至於詳細產生TFRecords檔的 python code方法,可以參考內文中的程式碼
在這篇 TensorFlow高效读取数据 中,官方提供了3種方法
供给数据(Feeding): 在TensorFlow程序运行的每一步, 让Python代码来供给数据。
从文件读取数据: 在TensorFlow图的起始, 让一个输入管线从文件中读取数据。
预加载数据: 在TensorFlow图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。 对于数据量较小而言,可能一般选择直接将数据加载进内存,然后再分batch输入网络进行训练(tip:使用这种方法时,结合yield 使用更为简洁,大家自己尝试一下吧,我就不赘述了)。但是,如果数据量较大,这样的方法就不适用了,因为太耗内存,所以这时最好使用tensorflow提供的队列queue,也就是第二种方法 从文件读取数据。对于一些特定的读取,比如csv文件格式,官网有相关的描述,在这儿我介绍一种比较通用,高效的读取方法(官网介绍的少),即使用tensorflow内定标准格式——TFRecords
至於詳細產生TFRecords檔的 python code方法,可以參考內文中的程式碼
[GDB] C/C++ Debugger
GNU Debugger
GDB 是 GNU Project Debugger的縮寫
是適合用在 Linux/MAC 上面的除錯工具
入門教學
首先,開始debug之前,請務必在command line 下指令時,在gcc或是g++後面加上 '-g' 這段文字[1]
下面是CS50所分享的使用教學影片
g++ - is using the “-g” flag for production builds a good idea?
How Does The Debugging Option -g Change the Binary Executable?
GDB 是 GNU Project Debugger的縮寫
是適合用在 Linux/MAC 上面的除錯工具
入門教學
首先,開始debug之前,請務必在command line 下指令時,在gcc或是g++後面加上 '-g' 這段文字[1]
下面是CS50所分享的使用教學影片
GDB1
GDB2
[1] 關於除錯(Debugging)選項 "-g"
要使用 gdb 那麼首先,在你 compile 程式的時候, 要加上 -g 的選項. (可以用-g, -g2, -g3具體請看 man gcc)。
通常如果程式不會很大,在 compile 的時候我都是用 -g3 的,因為如果你用到了 inline 的 function, 用 -g 去 compile 就無法去 debug inline function了.這時候就用到 -g2, -g3了,g後面的數字越大,也就是說 可以 debug 的級別越高.最高級別就是 -g3. --- Debugging with GDB (入門篇)
g++ - is using the “-g” flag for production builds a good idea?
How Does The Debugging Option -g Change the Binary Executable?
"-g tells the compiler to store symbol table information in the executable. Among other things, this includes:
- symbol names
- type info for symbols
Debuggers use this information to output meaningful names for symbols and to associate instructions with particular lines in the source."
- files and line numbers where the symbols came from
2017年3月10日 星期五
認知思維模式升級 ! 在互聯網時代,如何升級自己的大腦OS
OS是電腦中最重要的部份,負責掌管電腦的工作順序,各種資源分配等等
這個聽起來跟人的認知思維模式是不是有很大的相似之處?
例如,早上起來的時候第一件事情是做什麼,選擇繼續賴床還是?
吃完早餐之後到公司第一件事情做得是什麼?
身邊的人其實都是聰明人
那為什麼能夠達成一般人10倍到100倍,甚至1000倍收入的人這麼少???
反過來問,我該如何成為一般人1000倍甚至大於1000倍的收入呢?
除了成為公司的最高負責人或是高管以外,靠投資跟創業行不行?
在這篇<高收入,都是睡出来的>文章給我們一些方向 :
1、把单位时间卖贵;2、让时间可以被批量购买;3. 让时间产生复利
我們應該仔細檢視自己手上掌握的技能,握有的資源是不是同時能夠讓我們達到上面的事情?
Ex. 開發一款機器人理財系統,讓它在我們睡覺的時候繼續幫我們理財?
另一篇<认知升级,你不会经历比这更好的痛苦了>,提到了是否值得花錢去上課?
我想下面給出了一個解答
我问他,那有一些课,你花了这么多钱,没有达到你预期怎么样。
他回答说,首先,有没有学到东西,都是因人而异的。对我来说,牛人最牛逼的地方,在于认知层面的高阶,只要他们讲的其中一句话,或推荐的一本书,有可能给我带来不一样的思维方式,那就值回票价和时间了。
一个人之所以能成功,一定是拥有普通人缺少的特质。课讲的好不好只是很小的一方面,关键是做事的思维逻辑方式和风格,甚至整套运营的思路,都值得全方位整体去了解和学习。我们学的是更加高级的东西,而不只是关注内容而已。
这才是大格局的认知。
然而,认知的升级可以通过学习;比升级更重要的,是认知的迭代,而迭代,就是一个人的功课。
省錢真的能夠賺到大錢嗎 ? 我高度質疑這點
如果是牛人的課程,同時也是自己與市場上稀缺的能力
花費的學費未來一定能夠以數倍的方式回到自己身上
不先付出無形與有形的代價,哪能有任何收穫 ?
看到1000倍收入總是眼睛一亮
重點是在於,我們該如何打造符合我們自己性格,同時滿足上面3點性質的高收入工具
並且在有限的歲月中貫徹執行(有生之年能夠看到成果才是最重要的! 時間不等人)
高收入者與一般人,差別在哪,我想你我應該清楚
---------------------------------------------------------------
思想練習
Q : 我想要做得志業,是否能夠滿足上面提到的3點
訂閱:
意見 (Atom)