阳志平 先生在他的個人網誌上面撰寫了 語言學習方法 的文章
原文在此 阳志平 - 笨方法学语言
-----------------------------------------------------------------------------------------------------------------
文章中介紹 Gabriel Wyner 將學習語言拆解成了七個步驟,方便大家按照步驟進行學習
Gabriel Wyner的個人網頁、 他寫在 lifehacker上的個人故事
以下是內容的濃縮 :
步骤1:明白目标
学习语言要达到什么样的程度? 可參考 歐洲通用語言標準
步骤2:熟悉国际音标
步骤3:挑选高频词汇
步骤4:使用Anki对高频词汇进行间隔重复记忆
步骤5:利用高频词汇在社交日记网站写日记等
在 lang-8 網站(一開始的頁面就說 : Let our community of native speakers support your language
learning.)練習
步骤6:阅读感兴趣的文本,听感兴趣的音频材料
步骤7:沉浸
2016年9月29日 星期四
[學習筆記21] 機器學習基石 - Lecture 9 Linear Regression
提醒 :
這邊的章節推導等,會使用到大量的線性代數
可以以 MIT 的 Linear Algebra, Spring 2005 OCW 來作複習教材
------------------------------------------------------------------------------------------------------------
[Youtube 影片34 Linear Regression :: Linear Regression Problem]
前情回顧,學習可以在低 Ein 與 err 的情況,與有著目標分布的情況下進行
VC Bound 也能夠應用在不同的 error measure 上,也能夠應用在有noise的數據上

今天如果已經分類完之後,不需要再考慮客戶是否具備發卡資格(不再是是非題了)
轉而我們想要知道要給某個顧客"多少"信用額度
而我們的 Target function 是一個能夠輸出實數的式子,並且是正的實數
在這邊我們的輸出可以使用迴歸(Regression)分析[1]
實際上Regression輸出空間就是整個實數

那學習演算法該如何進行 ?
與前一個學習筆記20的內容類似
一樣是透過加權的方式算出一個分數,並以該分數來作為評斷依據
我們現在想要的就是這個實數與我們想要的值能夠越接近越好
和先前一樣,在原來的資料加上一個常數項 x0,使得式子能夠以 sigma 表示

x對應的是實數, y對應的是輸出結果
2D平面上,我們希望得到的這個線,與數據點 o 越接近越好
3D 立體空間上, 一樣希望得到一個平面,與這些數據點 o 越接近越好
同時餘數誤差(residual)越小越好

該如何衡量residual是大或小 ?
這邊的衡量方式是使用前面已經學習過的 squared error來進行計算 (採用原因請看統計學)
同樣分成 in-sample 與 out-of-sample 的計算方法,同時可能會有noise在我們的輸入輸出中


如何將 Ein(w)最小化 ? 如果能夠將Ein(w)變到最小,就可能可以進行機器學習
之後的影片中將會告訴我們如何辦到這件事

課後練習

Ans: 概念不難,邏輯上收入越高者,環款能力越好,可以給予的信用額度便越高

------------------------------------------------------------------------------------------------------------
[Youtube 影片35 Linear Regression :: Linear Regression :: Linear Regression Algorithm]
為了將整體的Ein算式能夠最簡潔的表達出來,在這邊決定以矩陣的方式進行表達
以下為推導過程:

因此,Ein(w)的式子可以轉變成圖八最後的式子
本節的任務就是求得圖九中所說的 min Ein(w)

Ein(w)是一個連續可微分的凸函數 (convex),存在最小值
這個最小值是凸函數的谷底,也就是最低點的地方,梯度是零(不能夠再往下滾, 即roll down)
我們的任務就是找到合適的 w,使得 Ein(w) 微分為零,便能夠求得Ein(w)的最小值
( 這邊先不考慮局部最小跟全域最小的問題 )

圖十一列出了Ein(w)的梯度公式,並將它展開,得到主要三項,w的2次式、1次式與常數項

若從一個維度開始推導,相當於將w的2次式進行微分,微分後的結果相當簡單
同樣的,改成對線性代數的部分進行微分
可以發現,即使以矩陣形式來進行表達,從結果來看,其實形式是一樣的

我們的任務只有一個,就是找到合適的w,使得 Ein 的梯度為零,即可得到最小值

若以psuedo inverse進行運算,可以求得w反矩陣,便能找到唯一解
大部分的情形,通常在資料數N遠大於 d+1的情況可以成立
若有很多組解的情況,便有很多種求解方法
從線性代數或是數值領域,可以知道常用的方法為何
若有現有的函式庫的話,老師建議直接使用
畢竟其他程式撰寫者已經最佳化了,我們不用重複做相同的任務

在這邊終於將輸入X與輸出Y進行一個分拆,透過計算psuedo-inverse
我們可以得到線性迴歸的解 !

透過線性代數這個強大的工具,可以輕易且有效的延伸到多維的空間

課後練習

Ans:
推導不出來y head = XWLin這個式子...

------------------------------------------------------------------------------------------------------------
[Youtube 影片36 Linear Regression :: ]
請問 : 線性迴歸 (Linear Rregression) 真的是機器學習嗎???
No = > 就像是一個一步可以求出(instantaneos)的公式化 (Closed-form) 答案
Yes => 從某些角度上,線性迴歸可以說是機器學習的演算法
因為它可以求得最佳化的Ein,同時也有好的Eout
同時透過 Psuedo inverse 就可以算出來,每次隨著 Psuedo inverse 的解而不斷進步
但實際上,求 Psuedo inverse 需要迭代好幾次
只是我們不知道程式在計算過程中發生什麼事情
只要最後的Eout(WLin)結果很不錯,那麼就有學習!

現在來求,抓一把起來之後的資料平均的Ein (Ein上面加一橫的符號)
它又稱作 noise level ,d+1是我們的自由度,N是我們的資料量
利用線性迴歸的特性,將下面的結果推出來 (完整的證明過程並沒有詳細說明)
y hat 是我們的預測結果,從前一講的課後練習可以知道 y hat = X(Xhat)y
統計學家稱XXhat 叫作帽子矩陣 (Hat Matrix)


理想的target function會落在 X 所展開的區域
因此,我們真正看到的 label 就是目標函數加上 noise 向量 (即y - yhat)
noise 就能夠由 (y-yhat) 轉變成 (I-H)
因此,Ein 與 Eout 的平均就能夠順利得到,如圖二十所示

有多少資料量,Ein 和 Eout 平均值的曲線圖 (VC Bound中的曲線不是平均)
如果資料筆數很大的情況底下,Ein 與 Eout 會收驗到 sigma 的平方
平均的error值會是 2(d+1)/N


課後練習

Ans:
選項1,H是對稱的
以下兩個選項可以透過證明得到
? 選項2,做了兩次投影,投影到相同的空間裡面
? 選項3,兩次轉換取餘數與一次轉換取餘數是一樣的

------------------------------------------------------------------------------------------------------------
[Youtube 影片37 Linear Regression :: ]
線性分類 vs 線性迴歸
NP-hard (non-deterministic polynomial-time hard) 名詞小解釋 [2]
線性分類 與 線性迴歸 的不同地方在於,它的輸出空間直接是實數,不再是 +1 與 -1
假設的輸出結果是wTx,錯誤量的衡量是(y hat - y)的平方
它是屬於有效率的分析解

線性迴歸真的能夠這麼快速的把結果算出來嗎? 如何從數學的角度來證明這件事情?

我們從圖形化的角度來比較兩個不同 error 運算方法之間的差異
可以知道 err 0/1 ≦ err sqr

從VC Dimension中,可以得到圖二十六的第一個不等式
在從剛剛上面的結論,我們就可以得到第二個不等式
由於err 0/1並不好解,所以我們換成 err sqr,因此我們的err hat是採用 err sqr
以寬鬆一點的Bound,比較容易得找到想要的解
因此,可以先用線性迴歸先取得 WLin 來當作PLA 或 pocket 演算法的初始參數 w0
來加速PLA演算法

課後練習

Ans:
? 畫圖出來可以得到這題的答案。
這三個答案選項都是機器學習中很重要的上限,之後會針對這個部分進行介紹

總結
介紹了線性迴歸的演算法,以解析的方式求得了線性迴歸的解
同時,新的Eout - Ein 大約等於 2(d+1) / N (d= 維度, N = 資料量)
線性迴歸之後會拿來用在二元分類問題上面,敬請期待 : P

------------------------------------------------------------------------------------------------------------
PS. 如果要打方程式,似乎以 Gitbook 做記錄更好
[1] 演算法筆記 - 迴歸分析
[2] 論P,NP, NP-hard, NP-complete問題
這邊的章節推導等,會使用到大量的線性代數
可以以 MIT 的 Linear Algebra, Spring 2005 OCW 來作複習教材
------------------------------------------------------------------------------------------------------------
[Youtube 影片34 Linear Regression :: Linear Regression Problem]
前情回顧,學習可以在低 Ein 與 err 的情況,與有著目標分布的情況下進行
VC Bound 也能夠應用在不同的 error measure 上,也能夠應用在有noise的數據上

圖一、前情題要
今天如果已經分類完之後,不需要再考慮客戶是否具備發卡資格(不再是是非題了)
轉而我們想要知道要給某個顧客"多少"信用額度
而我們的 Target function 是一個能夠輸出實數的式子,並且是正的實數
在這邊我們的輸出可以使用迴歸(Regression)分析[1]
實際上Regression輸出空間就是整個實數

圖二、信用卡額度上限問題
那學習演算法該如何進行 ?
與前一個學習筆記20的內容類似
一樣是透過加權的方式算出一個分數,並以該分數來作為評斷依據
我們現在想要的就是這個實數與我們想要的值能夠越接近越好
和先前一樣,在原來的資料加上一個常數項 x0,使得式子能夠以 sigma 表示

圖三、線性迴歸假說
x對應的是實數, y對應的是輸出結果
2D平面上,我們希望得到的這個線,與數據點 o 越接近越好
3D 立體空間上, 一樣希望得到一個平面,與這些數據點 o 越接近越好
同時餘數誤差(residual)越小越好

圖四、線性迴歸圖示
該如何衡量residual是大或小 ?
這邊的衡量方式是使用前面已經學習過的 squared error來進行計算 (採用原因請看統計學)
同樣分成 in-sample 與 out-of-sample 的計算方法,同時可能會有noise在我們的輸入輸出中

圖五、誤差量衡量方法

圖六、In-sample、Out-of-sanple誤差衡量方式
如何將 Ein(w)最小化 ? 如果能夠將Ein(w)變到最小,就可能可以進行機器學習
之後的影片中將會告訴我們如何辦到這件事
圖七、如何最小化Ein(w)
課後練習

Ans: 概念不難,邏輯上收入越高者,環款能力越好,可以給予的信用額度便越高

------------------------------------------------------------------------------------------------------------
[Youtube 影片35 Linear Regression :: Linear Regression :: Linear Regression Algorithm]
為了將整體的Ein算式能夠最簡潔的表達出來,在這邊決定以矩陣的方式進行表達
以下為推導過程:

圖八、Ein(w)矩陣形式
因此,Ein(w)的式子可以轉變成圖八最後的式子
本節的任務就是求得圖九中所說的 min Ein(w)

圖九、Ein 最小值
Ein(w)是一個連續可微分的凸函數 (convex),存在最小值
這個最小值是凸函數的谷底,也就是最低點的地方,梯度是零(不能夠再往下滾, 即roll down)
我們的任務就是找到合適的 w,使得 Ein(w) 微分為零,便能夠求得Ein(w)的最小值
( 這邊先不考慮局部最小跟全域最小的問題 )

圖十、convex
圖十一列出了Ein(w)的梯度公式,並將它展開,得到主要三項,w的2次式、1次式與常數項

圖十一、Ein(w)的梯度公式
若從一個維度開始推導,相當於將w的2次式進行微分,微分後的結果相當簡單
同樣的,改成對線性代數的部分進行微分
可以發現,即使以矩陣形式來進行表達,從結果來看,其實形式是一樣的

圖十二、線性代數分析
我們的任務只有一個,就是找到合適的w,使得 Ein 的梯度為零,即可得到最小值

圖十三、線性迴歸最佳化的任務
若以psuedo inverse進行運算,可以求得w反矩陣,便能找到唯一解
大部分的情形,通常在資料數N遠大於 d+1的情況可以成立
若有很多組解的情況,便有很多種求解方法
從線性代數或是數值領域,可以知道常用的方法為何
若有現有的函式庫的話,老師建議直接使用
畢竟其他程式撰寫者已經最佳化了,我們不用重複做相同的任務

圖十四、可逆、奇異矩陣
在這邊終於將輸入X與輸出Y進行一個分拆,透過計算psuedo-inverse
我們可以得到線性迴歸的解 !

圖十五、線性迴歸演算法
透過線性代數這個強大的工具,可以輕易且有效的延伸到多維的空間

圖十六、good routine
課後練習

Ans:
推導不出來y head = XWLin這個式子...

------------------------------------------------------------------------------------------------------------
[Youtube 影片36 Linear Regression :: ]
請問 : 線性迴歸 (Linear Rregression) 真的是機器學習嗎???
No = > 就像是一個一步可以求出(instantaneos)的公式化 (Closed-form) 答案
Yes => 從某些角度上,線性迴歸可以說是機器學習的演算法
因為它可以求得最佳化的Ein,同時也有好的Eout
同時透過 Psuedo inverse 就可以算出來,每次隨著 Psuedo inverse 的解而不斷進步
但實際上,求 Psuedo inverse 需要迭代好幾次
只是我們不知道程式在計算過程中發生什麼事情
只要最後的Eout(WLin)結果很不錯,那麼就有學習!

圖十七、
現在來求,抓一把起來之後的資料平均的Ein (Ein上面加一橫的符號)
它又稱作 noise level ,d+1是我們的自由度,N是我們的資料量
利用線性迴歸的特性,將下面的結果推出來 (完整的證明過程並沒有詳細說明)
y hat 是我們的預測結果,從前一講的課後練習可以知道 y hat = X(Xhat)y
統計學家稱XXhat 叫作帽子矩陣 (Hat Matrix)

圖十八、
線性代數 帽子矩陣 Hat Matrix
y是一個在N維空間的向量(y1~yn)
要預測y hat,先讓 y hat 在做線性迴歸前,以X 乘上一個任意的向量W,
將每一個 X 的 column作線性組合,展開(span)成一個空間
而y hat就在該空間中(如圖 紅色區域)
我們希望 y 與 y hat 差異越小越好,
H 是y投影到 y hat 的矩陣
trace是指對角線上的值
----------------------------------------
線性代數知識小補充
同學 :
老師您好
想請問一下在15頁裡為什麼這邊要特別用trace(I-H)來代表residual呢?
因為I-H會投影到span(X)的正交補空間
那麼用rank不是會比較有幾何意義嗎?
還是說trace在後面會有其他運用呢?
林老師回覆 : 在這個例子裡面,建議可以去推導一下,Rank 和 Trace 是有很強的關係
同學 :
推完才想起來投影矩陣對角化的形式會得出rank=trace

圖十九、
理想的target function會落在 X 所展開的區域
因此,我們真正看到的 label 就是目標函數加上 noise 向量 (即y - yhat)
noise 就能夠由 (y-yhat) 轉變成 (I-H)
因此,Ein 與 Eout 的平均就能夠順利得到,如圖二十所示

圖二十、
有多少資料量,Ein 和 Eout 平均值的曲線圖 (VC Bound中的曲線不是平均)
如果資料筆數很大的情況底下,Ein 與 Eout 會收驗到 sigma 的平方
平均的error值會是 2(d+1)/N

圖二十一、
從這邊推導的結果,以及前面推導VC Dimension的結果
我們有理由相信,在noise不大的情況底下,線性迴歸是學習演算法

圖二十二、

選項1,H是對稱的
以下兩個選項可以透過證明得到
? 選項2,做了兩次投影,投影到相同的空間裡面
? 選項3,兩次轉換取餘數與一次轉換取餘數是一樣的

[Youtube 影片37 Linear Regression :: ]
線性分類 vs 線性迴歸
NP-hard (non-deterministic polynomial-time hard) 名詞小解釋 [2]
線性分類 與 線性迴歸 的不同地方在於,它的輸出空間直接是實數,不再是 +1 與 -1
假設的輸出結果是wTx,錯誤量的衡量是(y hat - y)的平方
它是屬於有效率的分析解

圖二十三、
線性迴歸真的能夠這麼快速的把結果算出來嗎? 如何從數學的角度來證明這件事情?

圖二十四、
我們從圖形化的角度來比較兩個不同 error 運算方法之間的差異
可以知道 err 0/1 ≦ err sqr

圖二十五、
從VC Dimension中,可以得到圖二十六的第一個不等式
在從剛剛上面的結論,我們就可以得到第二個不等式
由於err 0/1並不好解,所以我們換成 err sqr,因此我們的err hat是採用 err sqr
以寬鬆一點的Bound,比較容易得找到想要的解
因此,可以先用線性迴歸先取得 WLin 來當作PLA 或 pocket 演算法的初始參數 w0
來加速PLA演算法

圖二十六、
課後練習

Ans:
? 畫圖出來可以得到這題的答案。
這三個答案選項都是機器學習中很重要的上限,之後會針對這個部分進行介紹

總結
介紹了線性迴歸的演算法,以解析的方式求得了線性迴歸的解
同時,新的Eout - Ein 大約等於 2(d+1) / N (d= 維度, N = 資料量)
線性迴歸之後會拿來用在二元分類問題上面,敬請期待 : P

圖二十七、總結
------------------------------------------------------------------------------------------------------------
PS. 如果要打方程式,似乎以 Gitbook 做記錄更好
[1] 演算法筆記 - 迴歸分析
[2] 論P,NP, NP-hard, NP-complete問題
2016年9月28日 星期三
[學習筆記20] 機器學習基石 - Lecture 8 Noise and Error
[Youtube 影片 30 Noise and Error :: Noise and Probabilistic Target @ Machine Learning Foundations]
第8講 Noise & Error 雜訊與錯誤
討論在有雜訊的情況底下該如何進行學習

X 是一個未知的資料分佈
我們的學習演算法A的任務就是從現有的資料與 Hypothesis set H裡面選出合適的hypothesis
好的Hypothesis是VC Dimension 有限個,而且Ein很小,由前面的內容就終於能夠進行學習

雜訊 Noise
可是,世界不如我們想像中的那般美好,可能資訊中會存在著錯誤
Input x, output y 都可能有雜訊存在
像是信用卡資訊填錯,在標記的時候,好客戶標記錯誤成壞客戶,抑或是A跟B標反同個資料
都會讓分類的時候出現問題

以彈珠實驗來作 VC Bound 的說明,我們在這邊可以說 : 橘色彈珠就是我們犯錯的地方



目標的分佈 Target Distribution of P (y|x)
從前面的核心概念延伸出來
由原本的目標函數 (Target Function) 變成有關於機率的目標分布(Target Distribution)
我們來探討其中一個 x 的目標,先稱作迷你目標 mini-target (因為只有一項)
以下將會針對目標分布進行解釋
目標分布的解釋方法 1
當預測某筆資料為 o 的正確機率為0.7, x 的正確機率為 0.3
從前面的結果,這邊最理想的猜測就是 o
因為正確的機率高達70%,錯誤的機率為30%
而錯誤機率30%,我們可以把它想像成雜訊
目標分布的解釋方法 2
前面所提到的Deterministic的目標 f,可以看作目標分布的其中一個特例
當 y = f(x) 的時候,P(y|x) = 1,當不相等的時候 P(y|x) = 0


最後,根據目標分布,我們可以將我們的學習流程改變成圖八的模式
同時,pocket algorithm 也依然適用新的學習流程


Ans :
選項 1. 如果是線性可分離的情況,w很容易可以得到,因此就不需要執行 PLA 演算法了
選項 2, 3 則是不一定如此,都可以舉反例推翻
 --------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------------
[Youtube 影片 31 Noise and Error :: @ Machine Learning Foundations]
誤差衡量 Error Measure
整個Learning flow中,我們最關心的就是 g 和 f 有沒有接近,並且能夠說服他人是如此
至於該怎麼說服呢 ? Eout(g) ?
更一般的來說,需要有一個誤差衡量的公式error measure來進行計算 E(g,f)
而這邊的 g 有三項特性 :
1. Out-of -sample : 只看未抽樣的 x
2. Pointwise : 看每個點的表現
3.Classification : 資料分錯或分對,稱為分類問題。而分類錯誤,我們通常稱為 0/1 error
因為不是分錯,就是分對,相當於邏輯上的 0 (對,付出零代價)或 1 (錯,付出所有代價)

以點為準的錯誤的衡量
很多的錯誤衡量方式,可以以每個點來作衡量
每個點上我們的衡量錯誤稱作 pointwise error measure,簡稱為 err

衡量錯誤的方法,包含 In-sample 與 Out-of-sample 兩部分
f(xn) 實際上就是 yn
只需要考慮每個點就好,不需要考慮每點之間的前後關係


兩個 err (Pointwise error measure) 的衡量方式 :
0/1 error 通常是使用在分類(Classification)上,是一種很明確與簡單的衡量方法
Squared error 則是使用在回歸問題(Regression)上,回歸通常是用來看誤差值有多大
而不是著重在到底有多準,後面會探討線性回歸與邏輯回歸的問題
Ex. 預測 pi,沒有要求得如 3.1415926 到小數點下很多位的精準
而是看說預測出來的 3.14 離真正的 pi 差多遠

現在來探討理想的 Mini-Target,探討雜訊(Noise)與錯誤量(error)之間的關係
左邊的例子1是 0/1錯誤衡量方法的例子
y = 2的時候,正確的機率是0.7,所以平均只需要付出錯誤量為 1-0.7 = 0.3的代價
因此在這邊選擇y = 2是合理的選擇
右邊的例子2是平方錯誤衡量方法的例子
y = 1.9的時候,發現在0/1錯誤衡量中表現最差的1.9卻有著最低的平均錯誤量 !
因此,這件事情告訴我們
每個選擇都有其個別意義,根據我們使用上的需求,來進行選擇較為明智
理想的最小目標




--------------------------------------------------------------------------------------------------------------
[Youtube 影片 32 Noise and Error :: Algorithmic Error Measure @ Machine Learning Foundations]
指紋辨識案例
以一個指紋辨識的例子來作說明,看使用者是不是這台電腦的擁有者
 圖十六、錯誤衡量的選擇
圖十六、錯誤衡量的選擇

超級市場的case
超級市場的錯誤分類情形,根據 false accept、false reject,我們可以列出一個成本表
如圖十八的圖右側的表格
1. 如果今天是 false accept,客戶會非常不開心,可能會損失更大,因此懲罰權重是10
2. 如果今天是 false reject,可能會給不該折扣的人折扣,對於公司的損失相對較小

CIA的case
CIA 判斷是否授權某員工進入特定系統的例子,也是與上一個超級市場的例子類似

錯誤衡量機制的演算法設計
考量到錯誤可能發生在資料的輸入與輸出資料中,我們的演算法要加入錯誤衡量的機制
但是生出真正的錯誤衡量機制有些困難,因此有兩個替代方案
來生成近似的err (並說服我們自己這是可信的XD)
Plausible (劍橋英語辭典 : seeming likely to be true, or able to be believed)
1. 0/1 : flipping noise 很小 - NP
2. Squared : 最小的高斯雜訊
Friendly


課後練習

Ans :
目標函數 f(xn) = 輸出值 yn

權重分類法
各種不同的情形下,有著不同的權重,就像試卷上不同題目,有著不同的分數一樣
在這邊我們把前一個影片的矩陣稱作成本矩陣 (cost matrix),表示方式如圖二十二所示
重要的項目給予較高的權重,反之則權重較低

由於與0/1 error的Ein不一樣
因此有著權重的 in-sample error我們在右上角加入權重符號 w
同時將權重加入

圖二十四提出了一個問題
PLA如果是線性可分割的話,不需要考慮權重的問題,跑完之後Ein是 0
但真實世界都是線性不可分割,如果手上的資料太多,PLA跑不完怎麼辦 ?
既然PLA跑不完,何不試試 pocket 演算法 ?
使用 pocket 演算法,則是調整成為與權重有關,如果比口袋中答案的權重來的大的話
則以新找到的權重 w 為主
但我們新改的演算法,是否能夠保證應用在Ein w上呢 ???

OK, 將上面的問題延續到這邊
下圖是原始問題還有與另一組原始問題類似的等效問題
在前面我們的成本矩陣如原始問題所示
今天在 y = -1, h(x) = +1 的情況,我們的懲罰權重是1000
由於電腦硬體效能上的問題 (什麼限制了計算 ? => 記憶體空間可能不夠)
我們是不是能夠將原始問題的成本矩陣轉化成裡面的懲罰權重都是1的成本矩陣 ?
當然可以! 結果一樣 !
同時,簡化之後問題也簡單了不少,為什麼呢 ?
簡化過後的問題,就相當於是 0/1 error 的問題
在等效問題中,1000的權重,轉化成資料複製1000次即可
相當於該運算以程式的迴圈重複執行1000次,這可是電腦比人類更擅長的事情
因此,左右兩邊的兩個成本矩陣實際得到的結果是一模一樣的
而Pocket演算法在右邊已經能夠適用,故轉化過後,也能適用 (這邊未證明)

最簡單是複製1000次之後,將結果丟到pocket中
但是處理的資料量可能相當大,記憶體容量有限,因此不會真的乘上1000次 (Virtual copying)
配合原來的pocket演算法,改成weighted pocket演算法
又因為不會真的乘上1000次,所以只需要知道到底我們拜訪這些容易搞錯的點會多頻繁 ?
從乘上1000次可以想見,這些點被拜訪的機率會比其他的點高1000倍
而這種有系統的延伸,稱作 Systematic Route,也稱作簡化 reduction (劍橋英語字典 : the act of making something, or of something becoming, smaller in size, amount, degree, importance, etc.)
這樣我們就能夠以類似的哲學應用到許多資訊工程的理論、演算法上

課後練習

Ans : 利用前一個影片的課後練習,可以得到包含權重的 Ein w 公式

N = 總資料筆數 = 1,000,000
h(x) = +1,所以只討論第一行,
所以結果就是 :
(1,000 * 10 + 0 * 999,990 ) / (N = 10的六次方) = 0.01

總結

第8講 Noise & Error 雜訊與錯誤
討論在有雜訊的情況底下該如何進行學習

X 是一個未知的資料分佈
我們的學習演算法A的任務就是從現有的資料與 Hypothesis set H裡面選出合適的hypothesis
好的Hypothesis是VC Dimension 有限個,而且Ein很小,由前面的內容就終於能夠進行學習

圖一、學習的整體流程
雜訊 Noise
可是,世界不如我們想像中的那般美好,可能資訊中會存在著錯誤
Input x, output y 都可能有雜訊存在
像是信用卡資訊填錯,在標記的時候,好客戶標記錯誤成壞客戶,抑或是A跟B標反同個資料
都會讓分類的時候出現問題

圖二、何謂雜訊
以彈珠實驗來作 VC Bound 的說明,我們在這邊可以說 : 橘色彈珠就是我們犯錯的地方

圖三、VC Bound與彈珠實驗
Deterministic marbles
先前的時候,我們推導VC Bound,是將罐子中的彈珠x取出,依據我們選擇的 hypothesis
看看預測的結果與目標函數 f 是否相符合
若預測正確,標記為綠色,若有預測錯誤,則標記為橘色
Probabilistic marbles
在這邊雜訊的意思,有一個真實的目標函數 f,但是取出的彈珠結果卻與 f 不相符
想像一個會隨時改變顏色的彈珠 (意思就是在資料處理過程中,可能會被標記錯誤)
變色的時間還有一個比例存在
有時候36%的時間是綠色,64%是橘色 (probabilistic marble)
至於我們要怎麼知道這個比例呢?
我們還是可以由抽樣的方式來得到這個比例的結果
由抽出來的當下立刻記錄 ! (i.i.d. => it is decided)

圖四、前後差異
而這個得到的結果 y,也要是取樣來的
由於整體的概念類似,同樣是以取樣的方式進行實驗
若將前面的 VC Bound 證明結果重新架構,還是能夠繼續沿用
( 請注意,這邊並沒有詳細的推導! )

圖五、VC Bound 與 發生機率
目標的分佈 Target Distribution of P (y|x)
從前面的核心概念延伸出來
由原本的目標函數 (Target Function) 變成有關於機率的目標分布(Target Distribution)
我們來探討其中一個 x 的目標,先稱作迷你目標 mini-target (因為只有一項)
以下將會針對目標分布進行解釋
目標分布的解釋方法 1
當預測某筆資料為 o 的正確機率為0.7, x 的正確機率為 0.3
從前面的結果,這邊最理想的猜測就是 o
因為正確的機率高達70%,錯誤的機率為30%
而錯誤機率30%,我們可以把它想像成雜訊
目標分布的解釋方法 2
前面所提到的Deterministic的目標 f,可以看作目標分布的其中一個特例
當 y = f(x) 的時候,P(y|x) = 1,當不相等的時候 P(y|x) = 0

圖六、目標分布
稍微回顧一下
我們的學習目標轉成為:
針對常取樣到的 (often-seen) 機率P(x),預測它的迷你目標 P(y|x),並且要越接近越好

圖七、學習的目標
最後,根據目標分布,我們可以將我們的學習流程改變成圖八的模式
同時,pocket algorithm 也依然適用新的學習流程

圖八、加入目標分布的學習流程
課後練習

Ans :
選項 1. 如果是線性可分離的情況,w很容易可以得到,因此就不需要執行 PLA 演算法了
選項 2, 3 則是不一定如此,都可以舉反例推翻

[Youtube 影片 31 Noise and Error :: @ Machine Learning Foundations]
誤差衡量 Error Measure
整個Learning flow中,我們最關心的就是 g 和 f 有沒有接近,並且能夠說服他人是如此
至於該怎麼說服呢 ? Eout(g) ?
更一般的來說,需要有一個誤差衡量的公式error measure來進行計算 E(g,f)
而這邊的 g 有三項特性 :
1. Out-of -sample : 只看未抽樣的 x
2. Pointwise : 看每個點的表現
3.Classification : 資料分錯或分對,稱為分類問題。而分類錯誤,我們通常稱為 0/1 error
因為不是分錯,就是分對,相當於邏輯上的 0 (對,付出零代價)或 1 (錯,付出所有代價)

圖九、錯誤衡量方法
以點為準的錯誤的衡量
很多的錯誤衡量方式,可以以每個點來作衡量
每個點上我們的衡量錯誤稱作 pointwise error measure,簡稱為 err

圖十、Pointwise 錯誤衡量方法
衡量錯誤的方法,包含 In-sample 與 Out-of-sample 兩部分
f(xn) 實際上就是 yn
只需要考慮每個點就好,不需要考慮每點之間的前後關係

圖十一、In-sample & Out-of-sample錯誤衡量方法
兩個重要Pointwise 錯誤衡量方法

圖十二、兩個重要Pointwise 錯誤衡量方法
兩個 err (Pointwise error measure) 的衡量方式 :
0/1 error 通常是使用在分類(Classification)上,是一種很明確與簡單的衡量方法
Squared error 則是使用在回歸問題(Regression)上,回歸通常是用來看誤差值有多大
而不是著重在到底有多準,後面會探討線性回歸與邏輯回歸的問題
Ex. 預測 pi,沒有要求得如 3.1415926 到小數點下很多位的精準
而是看說預測出來的 3.14 離真正的 pi 差多遠

圖十三、誤差衡量方法
現在來探討理想的 Mini-Target,探討雜訊(Noise)與錯誤量(error)之間的關係
左邊的例子1是 0/1錯誤衡量方法的例子
y = 2的時候,正確的機率是0.7,所以平均只需要付出錯誤量為 1-0.7 = 0.3的代價
因此在這邊選擇y = 2是合理的選擇
右邊的例子2是平方錯誤衡量方法的例子
y = 1.9的時候,發現在0/1錯誤衡量中表現最差的1.9卻有著最低的平均錯誤量 !
因此,這件事情告訴我們
每個選擇都有其個別意義,根據我們使用上的需求,來進行選擇較為明智
理想的最小目標

圖十四、理想的最小目標
所以,學完了這節之後,不但需要考慮目標分布
還要計算與尋找輸出結果的錯誤量 err 是最少的選項
延伸VC背後的哲學概念,在這邊依舊能夠適用,詳細的推導部分,在這邊則先省略不討論
有興趣的可以自行上網查閱其他資料

圖十五、加入錯誤量量測的學習流程
課後練習

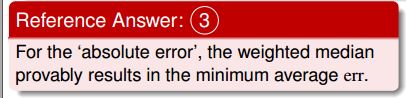
Ans :
沒搞懂選項3中,3 和 weighted median from P(y|x) 之間的關係是???
--------------------------------------------------------------------------------------------------------------
[Youtube 影片 32 Noise and Error :: Algorithmic Error Measure @ Machine Learning Foundations]
指紋辨識案例
以一個指紋辨識的例子來作說明,看使用者是不是這台電腦的擁有者
 圖十六、錯誤衡量的選擇
圖十六、錯誤衡量的選擇
False accept : 不是擁有者,但是卻接受了
False reject : 是擁有者,但是卻拒絕了
類似 True negative 與 False positive 的分類錯誤概念

圖十七、兩種分類錯誤
超級市場的case
超級市場的錯誤分類情形,根據 false accept、false reject,我們可以列出一個成本表
如圖十八的圖右側的表格
1. 如果今天是 false accept,客戶會非常不開心,可能會損失更大,因此懲罰權重是10
2. 如果今天是 false reject,可能會給不該折扣的人折扣,對於公司的損失相對較小

圖十八、超級市場的指紋檢驗
CIA的case
CIA 判斷是否授權某員工進入特定系統的例子,也是與上一個超級市場的例子類似

圖十九、CIA的指紋檢驗
錯誤衡量機制的演算法設計
考量到錯誤可能發生在資料的輸入與輸出資料中,我們的演算法要加入錯誤衡量的機制
但是生出真正的錯誤衡量機制有些困難,因此有兩個替代方案
來生成近似的err (並說服我們自己這是可信的XD)
Plausible (劍橋英語辭典 : seeming likely to be true, or able to be believed)
1. 0/1 : flipping noise 很小 - NP
2. Squared : 最小的高斯雜訊
Friendly
或是演算法設計上要夠友善,設計上要能夠達成 closed-form solution
或 convex objective solution,這兩個算法方式之後會在後面的課程中提及

圖二十、err演算法設計哲學
我們設計的學習演算法中,錯誤衡量機制理想上想要求得err,實際上是求出 err head
因為這才是可行的演算法設計哲學

圖二十一、含有err head的學習演算法
課後練習

Ans :
目標函數 f(xn) = 輸出值 yn

--------------------------------------------------------------------------------------------------------------
[Youtube 影片 33 Noise and Error :: Weighted Classification @ Machine Learning Foundations]
[Youtube 影片 33 Noise and Error :: Weighted Classification @ Machine Learning Foundations]
權重分類法
各種不同的情形下,有著不同的權重,就像試卷上不同題目,有著不同的分數一樣
在這邊我們把前一個影片的矩陣稱作成本矩陣 (cost matrix),表示方式如圖二十二所示
重要的項目給予較高的權重,反之則權重較低

圖二十二、成本矩陣cost matrix
由於與0/1 error的Ein不一樣
因此有著權重的 in-sample error我們在右上角加入權重符號 w
同時將權重加入

圖二十三、最小化權重分類的Ein w
圖二十四提出了一個問題
PLA如果是線性可分割的話,不需要考慮權重的問題,跑完之後Ein是 0
但真實世界都是線性不可分割,如果手上的資料太多,PLA跑不完怎麼辦 ?
既然PLA跑不完,何不試試 pocket 演算法 ?
使用 pocket 演算法,則是調整成為與權重有關,如果比口袋中答案的權重來的大的話
則以新找到的權重 w 為主
但我們新改的演算法,是否能夠保證應用在Ein w上呢 ???

圖二十四、尚未證明的想法
OK, 將上面的問題延續到這邊
下圖是原始問題還有與另一組原始問題類似的等效問題
在前面我們的成本矩陣如原始問題所示
今天在 y = -1, h(x) = +1 的情況,我們的懲罰權重是1000
由於電腦硬體效能上的問題 (什麼限制了計算 ? => 記憶體空間可能不夠)
我們是不是能夠將原始問題的成本矩陣轉化成裡面的懲罰權重都是1的成本矩陣 ?
當然可以! 結果一樣 !
同時,簡化之後問題也簡單了不少,為什麼呢 ?
簡化過後的問題,就相當於是 0/1 error 的問題
在等效問題中,1000的權重,轉化成資料複製1000次即可
相當於該運算以程式的迴圈重複執行1000次,這可是電腦比人類更擅長的事情
因此,左右兩邊的兩個成本矩陣實際得到的結果是一模一樣的
而Pocket演算法在右邊已經能夠適用,故轉化過後,也能適用 (這邊未證明)

圖二十五、連接Ein 0/1與Ein w
最簡單是複製1000次之後,將結果丟到pocket中
但是處理的資料量可能相當大,記憶體容量有限,因此不會真的乘上1000次 (Virtual copying)
配合原來的pocket演算法,改成weighted pocket演算法
又因為不會真的乘上1000次,所以只需要知道到底我們拜訪這些容易搞錯的點會多頻繁 ?
從乘上1000次可以想見,這些點被拜訪的機率會比其他的點高1000倍
而這種有系統的延伸,稱作 Systematic Route,也稱作簡化 reduction (劍橋英語字典 : the act of making something, or of something becoming, smaller in size, amount, degree, importance, etc.)
這樣我們就能夠以類似的哲學應用到許多資訊工程的理論、演算法上

圖二十六、加入權重後的pocket演算法
課後練習

Ans : 利用前一個影片的課後練習,可以得到包含權重的 Ein w 公式

N = 總資料筆數 = 1,000,000
h(x) = +1,所以只討論第一行,
所以結果就是 :
(1,000 * 10 + 0 * 999,990 ) / (N = 10的六次方) = 0.01

總結

圖、
訂閱:
意見 (Atom)