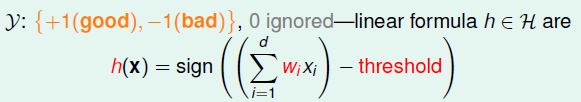自從AlphaGo在與南韓棋士李世石的圍棋對戰中取得了4勝ㄧ敗的好成績
背後的深度學習 (Deep Learning) 技術成為最近相當火紅的名詞
淺談Alpha Go所涉及的深度學習技術 ( Alpha GO 刊登在 Nature 上的論文 )
於是在這邊嘗試著用淺顯的語言試圖描述這個技術
以下的文章是目前看過講述深度學習最詳盡的文章
配合影片
一天搞懂深度學習 by 李宏毅教授
Wiki上寫得有點模糊,引述其中最重要研究里程碑的部分
深度神經網路是一種具備至少一個隱層的神經網路。與淺層神經網路類似,深度神經網路也能夠為複雜非線性系統提供建模,但多出的層次為模型提供了更高的抽象層次,因而提高了模型的能力。深度神經網路通常都是前饋神經網路,但也有語言建模等方面的研究將其拓展到遞迴神經網路[43]。卷積深度神經網路(Covolutional Neuron Networks, CNN)在電腦視覺領域得到了成功的應用[44]。此後,卷積神經網路也作為聽覺模型被使用在自動語音識別領域,較以往的方法獲得了更優的結果[45]。
簡單來說 Deep learning 是具備至少一個隱藏層(hidden layer) 半監督式的機器學習方法 (註1)
可以使用捲積式神經網絡( Convolution Neural Network, CNN )做為實現工具
至於什麼是CNN呢 ? 下面有一個簡短的影片對CNN的介紹 :
下面三張圖是 CNN 的示意圖
一起合併起來看算是很容易理解
基本上使用了捲積式神經網絡的技術
能夠在有了特定影像的輸入後,用來做下ㄧ步分類的動作


Convolution 做的事情是把特徵從影像中提取出來 (至於為什麼,需要翻閱論文來解答)
Pooling(池化) 則是因為需要分類 convolution 的時候產生過多的特徵,不但數量龐大,也容易發生過度擬合(overfitting)的現象。因此,池化是來進行特徵統計的動作,讓它們轉變成比較低維度的資料,也避免過度擬合現象
透過前述的方法對機器學習演算法進行訓練
我們能夠獲得一個具備有學習能力且高可性度預測能力的系統
(尚待補完)
註1 : 机器学习算法汇总:人工神经网络、深度学习及其它